
一个好的模型既要防止欠拟合又要避免过拟合,那么如何判断一个模型是否训练得刚刚好?本文将会带领大家通过loss曲线直观地认识过拟合(overfit)、欠拟合(underfit)、完美拟合(good fit)。
欠拟合
顾名思义,即拟合欠佳,也就是模型对训练集的学习能力不够。

如图所示,train loss下降的非常平缓,以至于似乎并没有下降,这说明模型根本没从数据中学到东西。造成这种情况的可能原因以及相应对策如下:
| 可能的原因 | 解决策略 |
|---|---|
| 模型结构太简单 | 适当增加模型复杂度(比如:增加网络层数和神经元数) |
| 权重初始化有问题 | 选择合适的初始化方案,如:全零初始化、随机正态分布、随机均匀分布 |
| 优化器和学习率不合适 | 一般的优化器用adam,行不通时要用SGD + 可调节的学习率(先大后小) |
| 训练时间不足 | 适当增大epoch,增加训练时间 |
| 数据集有问题 | 当噪声过大,或标注有大量错误时会使神经网络难以从中学到有用的信息 |
| 未归一化 | 将数据缩放到一定范围能解决尺度不平衡问题 |
过拟合
过拟合是指模型学过头了,以至于把一些噪声和随机波动也学进来了。如图所示,当Train loss还在继续下降时,valid loss在某一时刻已经不再下降反而上升了。

过拟合可能出现的原因及相应对策
| 可能的原因 | 解决策略 |
|---|---|
| 训练时间过长 | 从开始出现拐点的地方终止训练 |
| 模型过于复杂 | 适当增加L1、L2、dropout、batchnormalization正则化 |
| 数据量太少 | 适当增加训练数据或者减少模型参数 |
完美拟合
完美拟合是我们的最终目标,从图上直观看就是:train loss 和validation loss都收敛,并且中间相差很小很小。
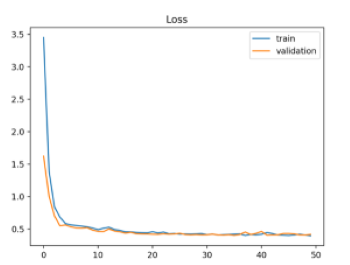
附loss曲线可视化代码:
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()